Python多线程的深入学习
做一个漏洞扫描器的时候偶然听到学长们聊Python的多线程是伪多线程,但是自己第一次知道,之前没有深入去了解过Python多线程具体的底层是什么样子的,遂学习记录一下,一直学习就好了。

Python中的并发任务
并发和并行
操作系统书本上的定义:并行是指两个或者多个事件在同一时刻发生;而并发是指两个或多个事件在同一时间间隔内发生。
在多道程序环境下,并发性是指在一段时间内宏观上有多个程序在同时运行,但在单处理机系统中,每一时刻却仅能有一道程序执行,故微观上这些程序只能是分时地交替执行。
Python中并发任务实现方式包含:多线程threading和协程asyncio,它们的共同点都是交替执行,而区别是多线程threading是抢占式的,而协程asyncio是协作式的。
什么是线程
线程也叫轻量级进程,是操作系统能够进行运算调度的最小单位,它被包涵在进程之中,是进程中的实际运作单位。线程自己不拥有系统资源,只拥有一点儿在运行中必不可少的资源,但它可与同属一个进程的其他线程共享进程所拥有的全部资源。一个进程可以有很多线程,每条线程并行执行不同的任务。
多线程执行任务实例:
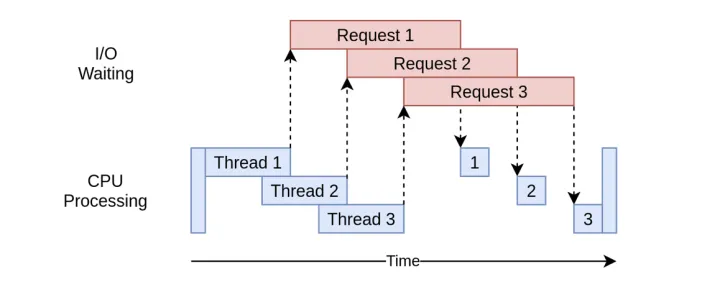
什么是协程
协程运行在线程之上,当一个协程执行完成后,可以选择主动让出,让另一个协程运行在当前线程之上。协程并没有增加线程数量,只是在线程的基础之上通过分时复用的方式运行多个协程,而且协程的切换在用户态完成,切换的代价比线程从用户态到内核态的代价小很多。协程和异步IO一起使用才会发挥最好效果。
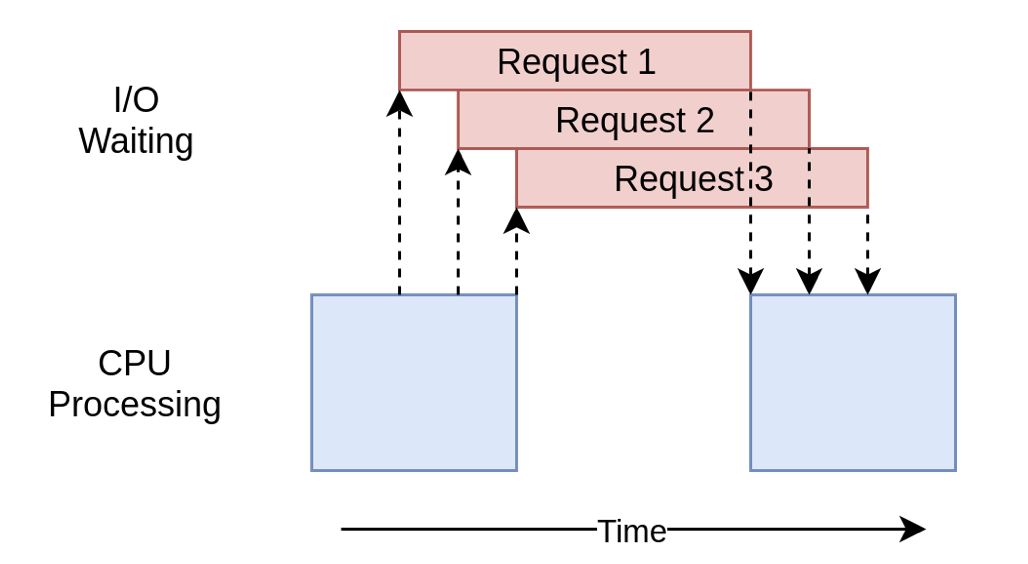
为什么说Python是伪多线程
全局解释器锁(GIL)
GIL的全称是全局解释器,来源是python设计之初的考虑,为了数据安全所做的决定。某个线程想要执行,必须先拿到GIL,我们可以把GIL看做是“通行证”,并且在一个python进程之中,GIL只有一个。拿不到线程的通行证,并且在一个python进程中,GIL只有一个,拿不到通行证的线程,就不允许进入CPU执行。GIL只在cpython中才有,因为cpython调用的是c语言的原生线程,所以他不能直接操作cpu,而只能利用GIL保证同一时间只能有一个线程拿到数据。
Python多线程下线程执行方式
1 | |
在非python环境中,单核情况下,同时只能有一个任务执行。多核时可以支持多个线程同时执行。但是在python中,无论有多少个核同时只能执行一个线程。究其原因,这就是由于GIL的存在导致的。
在Python3.2之前,GIL的释放逻辑是当前线程遇见IO操作或者ticks计数达到100 (ticks可以看作是Python自身的一个计数器,专门作用于GIL,每次释放后归零,这个计数可以通过 sys.setcheckinterval 来调整),进行释放。之后版本已经不是通过指令条数来切换了,而是时间间隔,采用sys.setswitchinterval。
而每次释放GIL锁,线程进行锁竞争、切换线程,会消耗资源。并且由于GIL锁存在,python里一个进程永远只能同时执行一个线程(拿到GIL的线程才能执行),这就是为什么在多核CPU上,python的多线程效率并不高。
这里需要注意一下:GIL只会对CPU密集型的程序产生较大的负面影响(主要完成计算任务的程序)
如何打破GIL锁的限制
- 如果完全使用Python来编程,可以使用
multiprocessing模块来创建进程池,多进程就可以避免GIL的限制 - 第二种方式是把重点放在C语言的扩展编程上。主要思想就是将计算密集的任务转移到C语言中,使其独立于Python,在C代码中释放GIL。
- 使用非官方解释器,比如JPython
Python 多线程、协程、多进程的使用
多进程
多进程适用于CPU运算密集型任务
使用multiprocessing
通过对Process类实例化之后获得一个进程p之后,通过p.start()就可以启动该进程了。p.join()方法就是让主进程进入阻塞状态,等对应的子进程执行完毕再执行下一行,主要用于进程同步。
这里采用Queue的方法进行进程间的通信,创建了一个接收进程和一个发送进程。
1 | |
注:参考的实例代码来自Python多进程详解 - 知乎 (zhihu.com)
concurrent.futures.ProcessPoolExecutor()
concurrent.futures 是 3.2 中引入的新模块,它为异步执行可调用对象提供了高层接口。可以使用 ThreadPoolExecutor 来进行多线程编程,ProcessPoolExecutor 进行多进程编程,两者实现了同样的接口,这些接口由抽象类 Executor 定义。这个模块提供了两大类型,一个是执行器类 Executor,另一个是 Future 类。执行器用来管理工作池,future 用来管理工作计算出来的结果,通常不用直接操作 future 对象,因为有丰富的 API。
一个判断是否为素数的实例:
1 | |
多线程
守护线程:只有所有守护线程都结束,整个Python程序才会退出,但并不是说Python程序会等待守护线程运行完毕,相反,当程序退出时,如果还有守护线程在运行,程序会去强制终结所有守护线程,当守所有护线程都终结后,程序才会真正退出。可以通过修改daemon属性或者初始化线程时指定daemon参数来指定某个线程为守护线程。
非守护线程:一般创建的线程默认就是非守护线程,包括主线程也是,即在Python程序退出时,如果还有非守护线程在运行,程序会等待直到所有非守护线程都结束后才会退出。
注:守护线程会在程序关闭时突然关闭(如果守护线程在程序关闭时还在运行),它们占用的资源可能没有被正确释放,比如正在修改文档内容等,需要谨慎使用。
threading
1 | |
利用lock机制,避免多个线程同时修改同一份数据:
1 | |
还有递归锁、信号量等多种机制避免数据竞争。
ThreadPoolExecutor
注意:当属于一个 Future 对象的可调用对象等待另一个 Future 的返回时,会发生死锁 deadlock
1 | |
注:concurrent.futures.as_completed(fs, timeout=None)
当通过 fs 指定的 Future 实例全部执行完毕或者被取消后,返回这些 Future 实例组成的迭代器。fs 中的 Future 实例可以被不同的执行器创建。任何在 as_completed() 调用之前就已经完成的 Future 实例会被最先生成。
协程
asyncio
1 | |
Python锁
- 同步锁(互斥锁):Lock,同步锁一次只能放行一个线程,一个被加锁的线程在运行时不会将执行权交出去,只有当该线程被解锁时才会将执行权通过系统调度交由其他线程。
- 递归锁:RLock(一次只能放行一个)递归锁是同步锁的一个升级版本,在同步锁的基础上可以做到连续重复使用多次acquire()后再重复使用多次release()的操作,但是一定要注意加锁次数和解锁次数必须一致,否则也将引发死锁现象。
- 条件锁:Condition(一次可以放行任意个)条件锁是在递归锁的基础上增加了能够暂停线程运行的功能。并且我们可以使用wait()与notify()来控制线程执行的个数。
- 事件锁:Event(一次全部放行)事件锁是基于条件锁来做的,它与条件锁的区别在于一次只能放行全部,不能放行任意个数量的子线程继续运行。
- 信号量锁:Semaphore(一次可以放行特定个)通过规定,成批的放行特定个处于“上锁”状态的线程,条件锁和事件锁放行的都是处于等待状态的线程